
Headless had its moment around 2018-2021. Contentful handled content, Shopify's Storefront API handled commerce, Stripe handled payments, and Auth0 handled identity. The pitch was the same everywhere: here's a powerful API, build whatever frontend you want on top of it.
The architecture made sense. The problem was that every headless tool required significant engineering investment to set up and maintain. Not just "hook up an API" investment, but "build a frontend, design a content model, configure preview environments, and own the deployment pipeline" investment. Most companies didn't have the engineering bandwidth to treat their CMS or commerce layer like a custom software project. And the ones that did often couldn't justify keeping a developer on it long-term once the initial build was done.
What headless actually cost you
The API-first model works well when you have engineers who treat these services like product infrastructure. When you don't, you get content teams staring at JSON editors and marketing waiting on engineering to change a checkout flow.
The headless CMS space is where this played out most visibly. Contentful started bolting on visual editing tools and composable page builders. Strapi added a content-type builder. Sanity shipped Sanity Studio with customizable desk structures. Every headless CMS slowly crept toward becoming a Digital Experience Platform, rebuilding the same workflows and interfaces they were supposed to eliminate.
The same pattern showed up in commerce. Shopify's headless Storefront API gave you full control, but building a custom storefront meant maintaining a React app, handling cart state, managing checkout flows, and syncing inventory. Most merchants went back to Shopify themes because the operational cost of maintaining a custom storefront wasn't worth it without dedicated engineering.
Headless vendors spent years telling you to decouple everything through APIs, then spent the next few years rebuilding the interfaces and workflows that monolithic tools already had. Non-technical users couldn't operate these systems independently, so the vendors built the interfaces back in. The result was headless architecture with monolithic complexity.
Visual development ate headless for lunch
Visual development tools showed up and solved a different problem: letting non-developers build and ship without waiting on engineering.
Tools like Webflow, Builder.io, and Framer gave marketing teams direct control over pages, layouts, and content without requiring a pull request. Builder.io went further by offering visual editing on top of existing codebases, a hybrid model where developers own the system and marketers own the pages.
Visual development grew while pure headless adoption slowed outside of enterprise. The hybrid approach (visual editing backed by APIs) turned out to be what most teams needed. You got the content API when you wanted it and a visual editor when you didn't want to bother engineering.
Headless started feeling like an architecture for teams with more developers than they knew what to do with. For everyone else, it was overhead.
Then LLMs learned to talk to APIs
Large language models can build working applications. But the more consequential thing they learned to do is talk to existing APIs and operate services through them.
This is what MCP (Model Context Protocol) made repeatable. You give an LLM access to a set of API tools, a CMS, a commerce platform, a payment processor, an analytics service, and it can read, create, update, and query through those APIs using natural language. No SDK wrappers to write. No frontend to build. You describe what you want, the model figures out the API calls, and the work gets done.
MCP isn't without its critics. Perplexity recently announced they're moving away from MCP internally in favor of their own Agent API, citing token overhead and authentication friction at scale. Those are real problems. But the pattern MCP established, LLMs operating through APIs via standardized tool definitions, is already showing up through function calling and agent APIs regardless of whether MCP itself becomes the long-term standard.
Sanity is a good example of this. Their content lake API is structured, their schemas are typed, and an LLM connected to Sanity can create documents, update fields, manage assets, and publish content through conversation. The same workflow that used to require a developer writing a custom integration now takes a .json tool definition and an API key.
This isn't limited to CMS. Any well-documented API with token-based auth works the same way. Stripe's API is so well-structured that models can create payment links, pull transaction data, and manage subscriptions through it. Shopify's Storefront and Admin APIs follow similar patterns. The developer who used to sit between the business team and the API? A model that already read the docs can do that job now.
You secure your API keys and set permissions like you always would. But the person using the system doesn't need to understand REST semantics or write fetch calls. They describe what they want, and the model handles the translation.
The developer dependency is dissolving
The core objection to headless was always operational, not architectural. Nobody argued that APIs were the wrong approach. The argument was always: "Sure, but who's going to build and maintain all of this?"
That was a fair objection when building meant writing React components, setting up preview environments, configuring webhooks, and debugging deployment pipelines. It's less of one when building means opening Claude Code and saying "set up a Next.js frontend that pulls content from our Sanity project and deploys to Vercel." Or "create a Shopify storefront with these products and connect Stripe checkout."
The developer's role shifts from implementation to architecture. You still need someone to design the data model, set up the deployment pipeline, and make security decisions. But the day-to-day work of building interfaces, managing data through APIs, and wiring services together? That's moving to the LLM, working through the API layers that headless tools already built.
Companies like Stripe, Shopify, and Sanity spent years building well-structured APIs, thorough documentation, and typed schemas. They did that work to support developer integrations. It turns out those same qualities (structured, documented, typed) are exactly what makes an API easy for an LLM to use. Every headless tool that invested in API quality accidentally built infrastructure that LLMs can now operate.
The stack I'm thinking about
Headless APIs (Sanity, Stripe, Shopify, Algolia, Clerk) as the service layer. An agentic coding tool (Claude Code, Cursor) as the builder. A frontend framework (Next.js, Astro) as the delivery layer. MCP or function calling as the bridge between the LLM and the APIs.
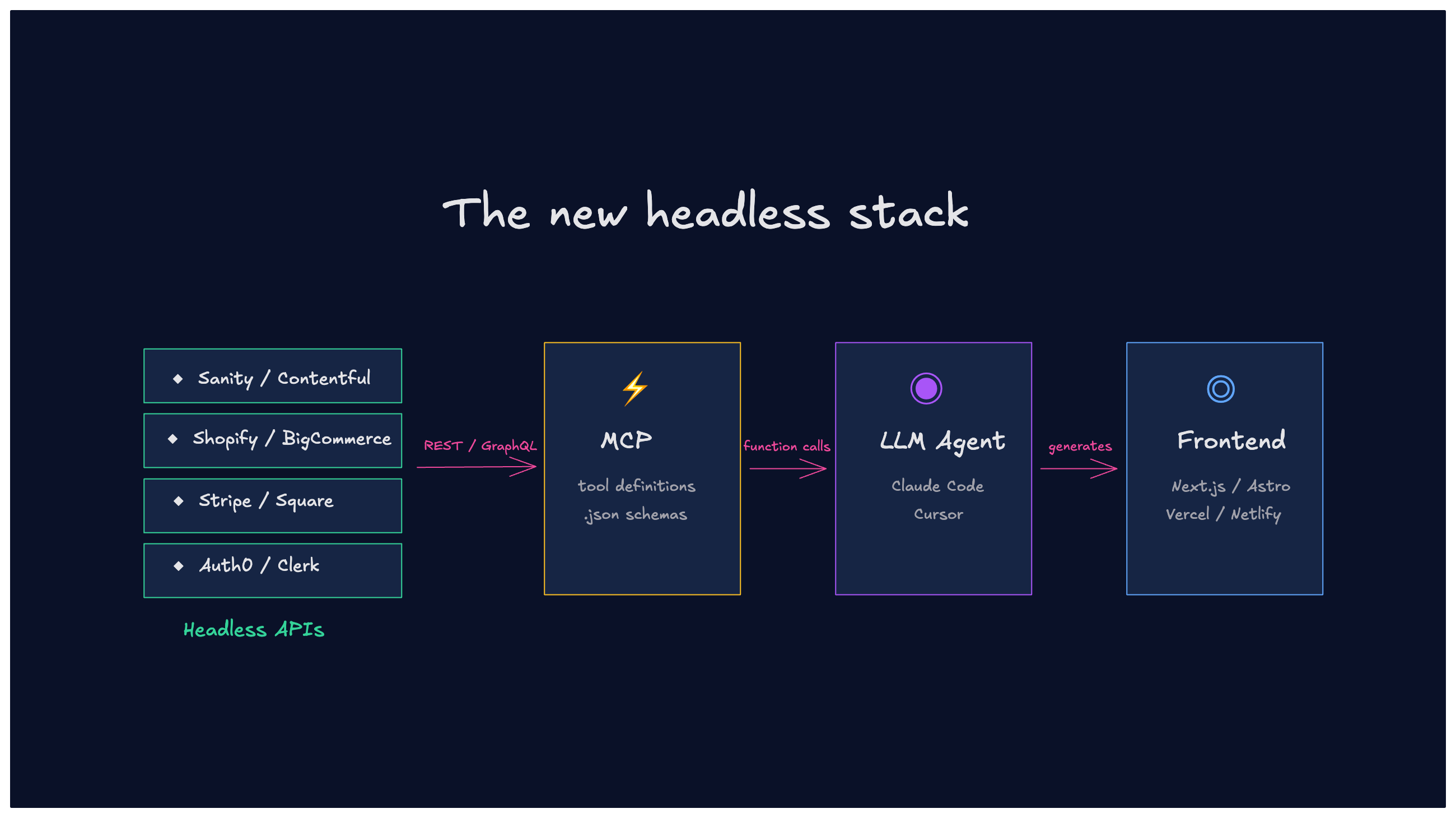
The team describes what they need, the LLM builds it through the APIs, and the developer reviews and maintains the architecture. Each service stays in its lane: Sanity handles content, Stripe handles payments, Algolia handles search.
I've used Claude Code connected to Webflow's CMS API through MCP to create and manage content programmatically. The experience is closer to pair programming with someone who already read the API docs than it is to traditional service administration. And every headless tool with a decent API is a candidate for this same workflow.
There's another layer to this. When a builder asks Claude Code or Cursor to build a newsletter, the model suggests specific APIs like Resend for email and gives a recommended option. Headless services aren't just competing for mindshare anymore, they're competing for LLM recommendations. How you show up in those suggestions matters, whether that's through llms.txt, AEO (Answer Engine Optimization), or having the cleanest docs and SDK in your category. Being one of the three options the model suggests is starting to matter the way ranking on the first page of Google used to.
What still needs to be true
This only works if the headless service has a well-designed API. Sanity's content lake API is structured and predictable, with typed schemas that an LLM can query and write to after seeing a few examples. Stripe is the gold standard here with consistent naming, thorough docs, and predictable error formats.
Where this breaks down:
- Undocumented edge cases - LLMs can only work with what's documented. If publishing requires a specific sequence of API calls that isn't in the docs, the model will get it wrong.
- Complex permissions models - Multi-tenant setups with role-based access and environment-specific publishing rules add friction that conversational interfaces don't handle gracefully.
- Asset management - Image uploads, transformations, and CDN invalidation involve binary data handling that's harder to do through natural language than CRUD operations on text content.
- Preview workflows - Showing unpublished content in context still requires frontend infrastructure. An LLM can create the content, but previewing it on a staging site is a deployment problem, not an API problem.
These explain why this isn't a "headless is fully back" story yet. It's closer to "headless lost for the wrong reasons, and those reasons are disappearing."
Headless lost a battle it might win retroactively
Visual development tools won because they removed the developer dependency for content operations. That was the right answer in 2022. But visual development still comes with tradeoffs. Proprietary rendering, platform lock-in, and a ceiling on what you can build before you need custom code. Most visual tools have APIs and integrations, but they're secondary to the canvas.
Headless architecture doesn't have those constraints. It's APIs and data structures that you can move between frameworks, host anywhere, and compose however you want. Non-developers could use it, but the moment they wanted something different from the initial build, the developer tickets started piling up.
LLMs and agentic building tools are filling that gap. The complexity of headless doesn't disappear, but it becomes something you can work through in conversation instead of code. The APIs and data models don't change. Who can operate them does.
I don't think the future is headless vs. visual. I think it's both, and the line between them is blurring. The platforms that treat their APIs as an afterthought are going to lose ground to the ones that invest in them. When an LLM can operate a CMS, a commerce API, and a payment processor through conversation, the visual editor becomes one interface among several, not the only way in.
And if that's right, a lot of companies that consolidated back to monolithic platforms in 2023 might be rethinking that decision.